













CopyRight©2019 ct96006.cn All Right Reserved 渝ICP备20008086号-41
清华大学发布AutoDroid - V2:移动设备AI自动化控制的创新性变革
2025-03-15 07:00:21
人气:0
编辑:96006资源网
近日,清华大学智能产业研究院(AIR)在2024年12月24日推出了一款名叫AutoDroid - V2的AI模型。此模型的发布有着明确的目标,那就是对移动设备的自动化控制能力予以优化。

AutoDroid-V2采用了一种基于脚本的方法,与传统依赖云端大型语言模型(LLM)的方式不同。这一创新使得设备能够高效执行用户指令,减少了对云服务的依赖,从而在隐私和安全性方面有了显著的提升。同时,它也降低了用户端的流量消耗及服务器端的运行成本,推进了移动设备的广泛应用。
在项目背景上,近年来,大型语言模型和视觉语言模型的崛起使得通过自然语言命令控制移动设备成为可能。这些技术为复杂用户任务的解决提供了新的途径。然而,传统的 “逐步 GUI 智能体” 方法存在着高流量消耗和隐私安全风险的问题,使得大规模部署面临障碍。
AutoDroid-V2的创新之处在于,它能够根据用户指令生成多步骤脚本,进而一次性执行多个 GUI 操作。这种方式大幅减少了查询频率,降低了资源消耗,并且能够在用户设备上直接生成和执行任务脚本。该模型在离线状态下会构建应用程序文档,为后续的脚本生成打下基础。
在性能测试中,AutoDroid-V2在23款移动应用上进行了226项任务的基准测试,相较于之前的模型,如 AutoDroid 和 SeeClick 等,任务完成率提升了10.5% 到51.7%。此外,其输入和输出的 token 消耗分别减少至43.5分之一和5.8分之一,模型推理延迟降低至原来的5.7到13.4分之一。这些成果显示了 AutoDroid-V2在实际应用中的高效性和可靠性。
清华与微软联合突破:Differential Transformer革新AI聚焦能力,精度跃升30%以上
近日,大语言模型(LLM)领域取得了飞速进展,Transformer架构作为其中的佼佼者,其价值不容小觑。Transformer模型的精髓,在于其创新的注意力机制,它如同一位高明的图书管理员,能从浩瀚的文字海洋中筛选出最关键的信息片段。

尽管如此,Transformer偶尔也会面临挑战,正如我们在信息爆炸的环境中寻找 needle in a haystack(针尖大海捞针),即便拥有高级筛选工具,也可能因海量冗余数据而影响其高效的识别与处理能力。
这种注意力机制产生的无关信息,在论文中被称为注意力噪音。想象一下,你想在文件中找一个关键信息,结果Transformer模型的注意力却分散到各种无关的地方,就像一个近视眼,看不清重点。
为了解决这个问题,这篇论文提出了Differential Transformer (DIFF Transformer)。这个名字很高级,但原理其实很简单,就像降噪耳机一样,通过两个信号的差异来消除噪音。
Differential Transformer 的核心是差分注意力机制。它把查询和键向量分成两组,分别计算两个注意力图,再将这两个图相减,得到最终的注意力分数。这个过程就像用两台相机分别拍摄同一个物体,然后将两张照片叠加,差异的地方就会凸显出来。
通过这种方式,Differential Transformer 能够有效地消除注意力噪音,让模型更加专注于关键信息。就好比你戴上降噪耳机,周围的噪音消失了,你就能更清晰地听到想要的声音。
论文中进行了一系列实验,证明了Differential Transformer 的优越性。首先,它在语言建模方面表现出色,只需要Transformer65% 的模型大小或训练数据,就能达到类似的效果。
其次,Differential Transformer 在长文本建模方面也更胜一筹,能够有效地利用更长的上下文信息。
更重要的是,Differential Transformer 在关键信息检索、减少模型幻觉和上下文学习方面表现出显著优势。
在关键信息检索方面,Differential Transformer 就像一个精准的搜索引擎,能够在海量信息中准确地找到你想要的内容,即使是在信息极其复杂的场景下,也能保持高准确率。
在减少模型幻觉方面,Differential Transformer 能够有效地避免模型“胡说八道”,生成更准确、更可靠的文本摘要和问答结果。
在上下文学习方面,Differential Transformer 更像是学霸,能够快速地从少量样本中学习新知识,而且学习效果也更加稳定,不像Transformer那样容易受到样本顺序的影响。
此外,Differential Transformer 还能有效地降低模型激活值中的异常值,这意味着它对模型量化更友好,可以实现更低比特的量化,从而提高模型的效率。
总而言之,Differential Transformer 通过差分注意力机制有效地解决了Transformer模型的注意力噪音问题,并在多个方面取得了显著的改进。它为大语言模型的发展提供了新的思路,未来将会在更多领域发挥重要作用。
清华大学科研突破:首推3D成像超级显微镜,成就多项全球首创
近日消息,清华大学官方公众号公布,其研究团队已成功研发出全球首台三维成像介观活体超高清显微镜RUSH3D,此技术革新实现了对大脑结构的深度透视,能够首次实现大规模细胞间相互作用的全景式观测,开启了生物医学研究的新篇章。

RUSH3D 介绍
该仪器具有跨空间和时间的多尺度成像能力,填补了当前国际范围内对哺乳动物介观尺度活体三维观测的空白,为揭示神经、肿瘤、免疫新现象和新机理提供了新的“杀手锏”,使我国生命科学家、医学家能够率先使用我国自主高端仪器设备来解决重大基础研究问题。
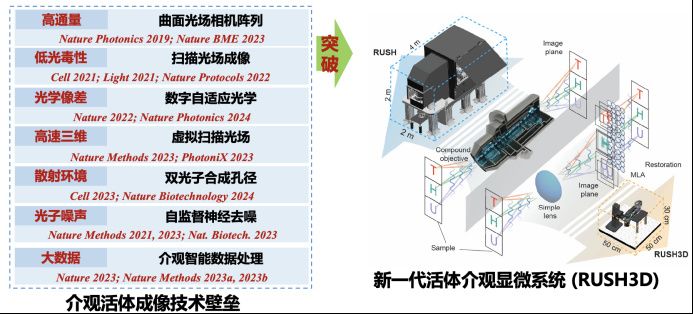
研究团队介绍,在兼具厘米级三维视场与亚细胞分辨率的同时,该仪器能以 20Hz 的高速三维成像速度实现长达数十小时的连续低光毒性观测。
相比当前市场上最先进的商业化荧光显微镜,该仪器在同样分辨率下的成像视场面积提升近百倍,三维成像速度提升数十倍,有效观测时长提升上百倍。

项目成果
目前,研究团队利用 RUSH3D 系统在脑科学、免疫学、医学与药学等多学科产出一系列成果,实现了多个“世界首次”:
首次在活体小鼠上以单细胞分辨率实现了覆盖大脑皮层 2/3 层的高速长时程三维观测,捕捉了多感官刺激下皮层各脑区的各异性响应模式,能够连续多天以单神经元精度追踪大规模神经响应
首次观测到急性脑损伤后多脑区的免疫反应,发现大量中性粒细胞从非血管区域往脑内的迁移与回流过程
首次在小鼠免疫反应过程中同时观测到了淋巴结内多个生发中心的形成过程,以及 T 细胞在不同生发中心之间的迁移现象。

团队介绍
该团队由中国工程院院士、清华大学自动化系教授戴琼海带领,自 2013 年起率先开展介观活体显微成像领域研究。
项目意义
研究团队负责人表示,该仪器的研制与产业化填补了对复杂生命现象介观尺度活体观测的空白,标志着我国在活体介观显微成像领域持续引领国际发展,极大提升了我国高端科研仪器的研究和应用水平,为人类探索生命奥秘打开了新的维度。
智源重磅开源:See3D模型引领无标注视频学习3D生成新潮流
下一篇:SpaceX星际飞船进展:第五艘原型SN20就位发射台,静候首次轨道试飞
相关文章
-
英伟达RTX 40系显卡产量大幅缩减一半,黄仁勋确认:Blackwell样品即将寄送,本周揭晓10-03
编辑:96006资源网
![英伟达RTX 40系显卡产量大幅缩减一半,黄仁勋确认:Blackwell样品即将寄送,本周揭晓]()
-
家暴男子在离婚法庭上扛起妻子就跑,网友炸了01-16
编辑:96006资源网
-
AMD战略聚焦:优先扩大客户端显卡版图,旗舰产品部署非当前首要议程02-10
编辑:96006资源网
![AMD战略聚焦:优先扩大客户端显卡版图,旗舰产品部署非当前首要议程]()
-
升级iOS 18后iPhone 15系列状况连连:显著续航缩水引用户热议08-27
编辑:96006资源网
![升级iOS 18后iPhone 15系列状况连连:显著续航缩水引用户热议]()
-
成都神兽归笼失败,开学第一天提前放学!10-31
编辑:96006资源网
![成都神兽归笼失败,开学第一天提前放学!]()
-
真实肤色:三星显示技术再创行业标杆,获Pantone肤色与色彩双认证09-20
编辑:96006资源网
![真实肤色:三星显示技术再创行业标杆,获Pantone肤色与色彩双认证]()